Dataset
The dataset consists of paired face images/video frames and speech audio samples collected from multiple speakers across different languages. The data is obtained from YouTube videos, consisting of celebrity interviews along with talk shows, and television debates. The visual data spans over a vast range of variations including poses, motion blur, background clutter, video quality, occlusions and lighting conditions. Moreover, most videos contain real-world noise like background chatter, music, over-lapping speech, and compression artifacts, resulting into a challenging dataset to evaluate multimedia systems.
Modalities
- Audio: Speech segments
- Visual: Face images or face tracks
- Labels: Speaker ID
Data Splits
- Training set
- Validation set
- Test set (labels hidden)
Missing Modality Setup
- Missing modalities occur only at test time
- Missing modality is explicit and complete (face modality absent)
- Training data always contains both modalities
Dataset access
The dataset is available on the following links:
- MAV-Celeb v1
Baseline systems
We provide multiple baseline systems to help participants get started with the challenge. These baselines cover different modality configurations and fusion strategies:
- Audio-only baseline: Speaker identification using only audio features
- Face-only baseline: Speaker identification using only visual features
- Late-fusion multimodal baseline: Combining predictions from both modalities
- Modality-dropout baseline: Training with random modality dropout to handle missing modalities
Link to the paper:
Fusion and Orthogonal Projection for Improved Face-Voice Association
Link to the Baseline code:
https://github.com/msaadsaeed/polysim
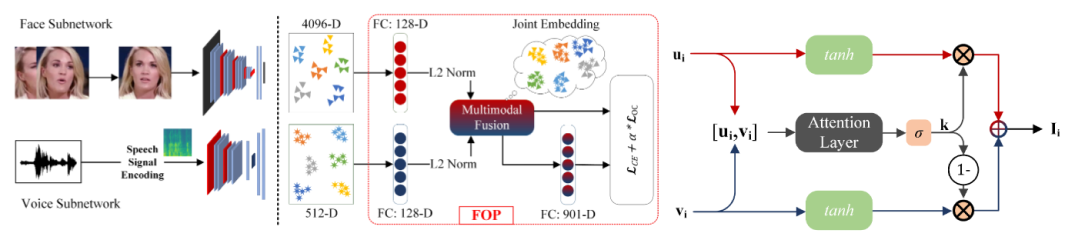
Figure 1: Diagram showing our baseline methodology.