Introduction
Can you identify a speaker across languages when you can't see their face? Or when you can't hear their voice?
The POLYSIM 2026 Challenge tackles this critical question in multimodal biometrics.
Recent years have seen significant advances in multimodal biometric systems that leverage both facial and
vocal characteristics for speaker identification. However, real-world applications often face scenarios where
one modality is unavailable due to technical constraints, privacy concerns, or environmental factors.
The POLYSIM 2026 Challenge addresses these real-world multimodal biometric scenarios where facial or vocal
data may be unavailable. Participants will develop robust speaker identification systems that maintain
accuracy across multiple languages (polyglot) even when face or voice modality is completely missing.
This challenge simulates practical constraints in biometric systems, addressing the critical question:
"Can speakers be accurately identified across multiple languages when only partial multimodal information is available?"
To support this research, we provide the Multilingual Audio-Visual (MAV-CELEB) dataset, containing
human speech clips of 154 identities with multiple language annotations extracted from various videos uploaded
online. The dataset enables investigation of speaker identification across languages while handling missing
modality scenarios, addressing both the polyglot and incomplete data challenges that are prevalent in
practical applications.
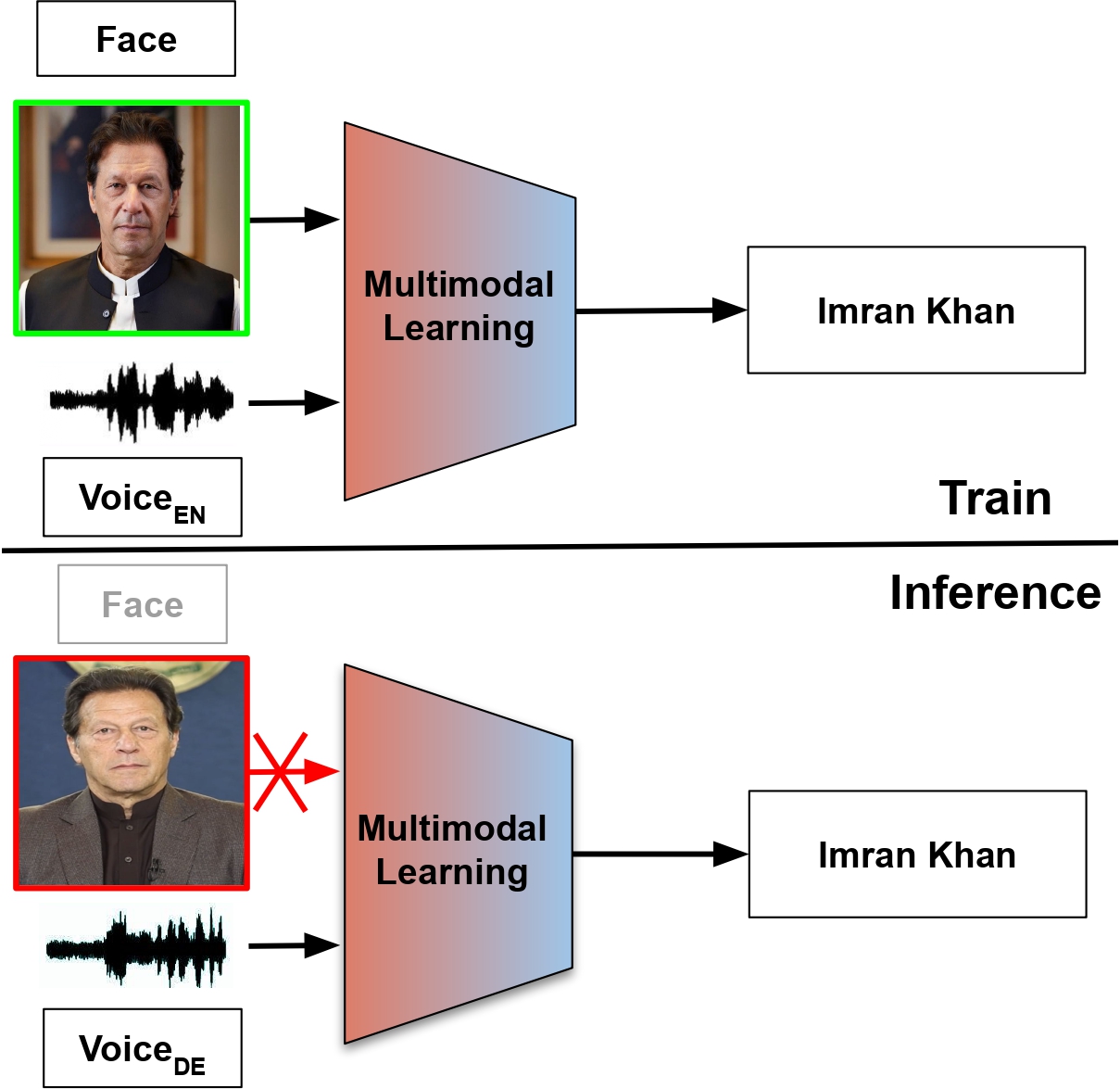
Figure 1: Diagram showing multimodal speaker identification across multiple languages with missing modality scenarios.
Quick facts
- 📊 Dataset: 154 identities across multiple languages
- 🎯 Task: Speaker identification with missing modalities
- 🏆 Venue: ACM MM 2026 Grand Challenge
- 📈 Metric: Top 1 Accuracy